 |
Pliny Workbench with WordHoard |
 |
2. Introduction
In a recent talk at the University of Illinois entitled Pliny: 4 perspectives, I tried to answer the question Pliny: what is it? in four fundamentally different ways:
- as a software tool to support notetaking and interpretation development traditional humanities research,
- as a way to think about software development for humanities tools that promotes more intimate interaction between those tools,
- as a device to promote thinking about some aspects of what interpretation is about in the humanities, and
- as a prototype, and as a piece of practice-lead research
As a result of Pliny’s winning of an MATC award from the Mellon Foundation in late 2008, we were able to take on a project focusing on Pliny in this second sense, and to allow us to explore (both from a technical/development sense, but also in terms of the user’s experience) some new ways that separately developed digital applications can work intimately together to support scholarship with Pliny. The article Playing together: modular tools and Pliny describes some of the background to this, and explains how Pliny’s modularity grew out of and was built on top of Eclipse’s plugin architecture. My interest in Pliny’s modularity, and the evident potential of the Eclipse/plugin framework to both support tool modularity through a new way of thinking about integration between tools, grew out of my evolving understanding of the nature of traditional scholarship and the implications of this for digital resources of all kinds.
Readers of this paper may well recall Vannevar Bush’s observation in his famous article As We May Think (in section 6, where he introduces the idea of the Memex machine) that the mind works to form associations between objects. As we all know, this key insight fuelled a great deal of the research and innovation in hypertext which has, through the WWW, had a profound affect on the role of computing in our daily lives. But it is important to realise that much of this work – particularly the WWW itself – was not entirely true to Bush’s vision. One of the important differences was in the Memex’s ability to allow its user to him/herself create connections (described by Bush as “trails”) between objects. His Memex machine allowed material from different documents to be projected at the same time in different screens on the machine, and the scholar could at any time be able to establish a link between them – the machine allowed one to make personal mental association visible and permanent. At any point in the future the Memex would be able to present these two pages as linked together. Inspired, then, by the Memex, Pliny has been built in such a way that the individual research can link two documents together. Furthermore, because digital materials can come in more than one media, the scholar using Pliny is able to link a web page to a page in a PDF document, or can link a portion of an image to notes s/he has taken about a printed book, or other combinations among the media that Pliny supports.
Although Pliny, as it comes out of the box, supports Web page annotation, PDF’s and images (and notetaking for materials that are not digital), it was written from the very start in such a way that it could be extended to support other digital media as well, such as video, audio, or 3D objects (and indeed, the Pliny Workbench would provide a framework to allow a user to load Pliny-aware players for these other media if they wanted them). By providing these tools in an integrated context of notetaking and the subsequent handling of these notes outside of their original context, Pliny draws our attention away from too tight a focus on the adding oa annotation to websites, and towards recognising the purpose of creating these personal annotations in the first place: to support personal scholarship by recording and presenting connections between materials as they arise in the mind of the scholar through his/her work, by recording original thoughts (as original annotations) as these objects are studied, and then as a way of incorporating these thoughts into a structure of interpretation that may (indeed, often will) incorporate personal insights that arise from the reading of a range of separate documents. Annotation tools attached to any single web-accessible resource simply cannot, in and of themselves, support substantial scholarly work that must range over a numer of different materials in this way.
In my view, adding annotation services to an existing website -- the current efforts of many developers -- is the wrong way to think about it. We can see the problem with this “adding an annotation service” approach if we consider annotation on paper:

When the book reader writes on the page he combines onto that piece of paper two rather different applications that then must co-exist: the print media represented by the printed word and his/her annotation shown by the handwritten note. The owner, the technology and purpose of these two co-existing texts – the annotation and the print material – are quite different. Furthermore, whereas the printed text represents an endpoint in the “publishing application” that put it there, the hand-written annotation represents the beginning of an act of interpretation that is likely to continue into the future. In some senses, then, a printed page with an annotation on it represents a nexus between these two quite different applications: the presentation of the print, and the support for the annotation made by the individual reader. The oddness, then, of the annotation-as-a-resource service in a web resource is brought into clearer focus when we realise that if handwritten annotation on a printed page worked in the way that an annotation service on a website would operate , it would have to be a service provided by the book’s publisher – something that would seem very peculiar, and, indeed perhaps strikingly inappropriate.
Pliny is focused on personal annotation and is, therefore, not a website, but an application that runs on its user’s machine. In this sense, it is like Word or Photoshop and must be installed on the user’s personal computer before it can be used. By not being a website, it can be much more flexible about the kinds of resources it is able to work with, and (by not being served, itself, from the web) allows these materials to not only be different kinds, but also to be assembled from anywhere across the Internet and perhaps not even served over the internet at all.
My thinking about Pliny and its potential to be readily extended to support other kinds of media made it evident to me that Pliny’s support for annotation need not be limited to relatively static media such as web pages or PDF files or digital video, but could extend to the displays generated by potentially more complex, interactive, and independently developed applications, as long as the developer of each of these applications wrote it in such a way that it was Pliny-aware. See the following figure, which shows schematically how this works:
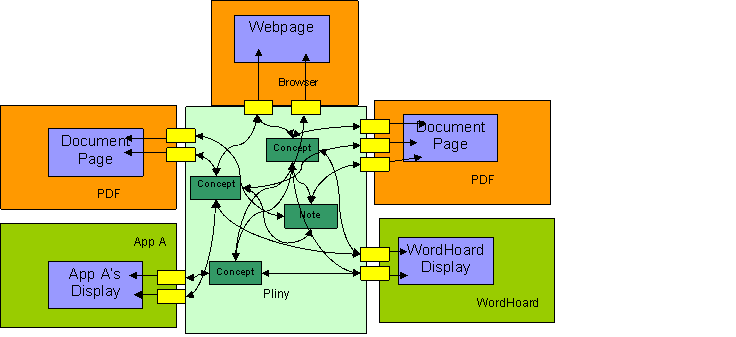
This figure shows different applications (shown as orange and green boxes) that present separate media objects to the Pliny user. The top three orange applications (already incorporated into basic Pliny) present PDF and web pages within Pliny and, by being “Pliny aware”, are able to support their annotation (shown as yellow boxes). These yellow boxes, as well as being annotations attached to a Web page or a page of a PDF file, can also be referenced, linked, and displayed, in other contexts – shown as being assembled and connected to new personal concepts in Pliny’s application area. Pliny, then, provides, then, a kind of glue (or a kind of web) that connects references to documents of various kinds to the user’s set of ideas that are also stored in Pliny.
Note, however, the bottom two green boxes to the left and right of the Pliny box. These represent two Pliny-aware applications (an imaginary “App A”, and the real WordHoard) that, based on the work done in this project, could be added by anyone to their Pliny installation. Here, instead of being applications like Pliny's PDF annotator that merely displays static material in media files, they represent dynamic applications that the user invokes and then uses to explore other kinds of data. In this view of the integration between the application and Pliny, displays that these applications generated from their data can also be annotated, and these annotations can also be integrated into the user’s set of ideas that are represented within Pliny.
The Mellon MATC prize allowed this issues behind this idea to be explored. Was the integration of a complex application with Pliny to handle notetaking within that application, really practical? How did the act of supporting annotation in the Pliny context affect how the application had to be written? What, if any, were the technical constraints under which such an application would have to be written if it was to support personal annotation of the results it generated, and now onerous was it for developers? We had already explored the development of extensions to Pliny that would allow a user to annotate a GoogleMap, and to work with image data from the image archive provided through the Victoria and Albert’s public API (http://www.vam.ac.uk/api), so we had a partial understanding of these issues – but these applications where exploratory in nature, and hence both relatively small and based on only a subset of the full potential of the mechanisms upon which they were based. Could this idea really work when the application was more complex?
I was aware of Martin Mueller and Northwestern University’s WordHoard project before the MATC aware had been granted, and had wanted even then to try out the idea of developing a version of WordHoard that would integrate with Pliny. Here was software that, instead of running as a web application in a browser, ran from a Java application. Its orientation towards allowing the user to browse and search documents, and to perform various kinds of word-oriented searches on them, plus its host of different kinds of presentations that could arise from this word-oriented work was an excellent trial application. As a result, I proposed to Mellon that the money that they had awarded to Pliny would fund a developer half-time for about two years who would take the WordHoard code and gradually adopt it so that it could run in the context in which Pliny ran, and that could support the Pliny-supported annotation of its displays.
WordHoard was written as a conventional Java application, using Java's Swing technology to implement its user interface. What is the difference between this, and the building of applications as plugins in the Eclipse manner (as Pliny is)? One of the important differences is that the Eclipse approach allows a more interdependant kind of interaction between two separately written software components than what Java's Swing made practical. With a conventional Java applications one can indeed include components that come from other developers (the Hibernate package, for example, is used inside WordHoard). However, these separate components often disappear inside the larger packaging—the main application becomes, let us say, a "Borg application", reusing software development work from others as a way to implement aspects of the software that they need, but hiding them inside its own packaging. In some sense the master project is a big tent containing many different parts that it has swallowed up, and users will see primarily the enveloping application as the thing they are using. Pliny, by virtue of operating in the Eclipse/plugin framework, is not a Borg application in this sense. The different applications shown as boxes in the figure above continue to be visible to the user, They can interact with each other at their boundaries, and can share screen space with each other. This supports the interesting nature of applications built this way: the components can be built separately and yet interact much more closely together than what happens in conventional application development.
John Bradley
Center for Computing in the Humanities
King's College London