
John Bradley
Centre for Computing in the Humanities
King’s College London
john.bradley@kcl.ac.uk
The Pliny project (Pliny 2006-8) was started in 2005, and has focused so far on the development of a piece of software, also called Pliny, which is meant to act as a thought-piece intended to draw attention to some potential there is in computing to support the personal and traditional side of scholarship. I gave a full presentation about this aspect of Pliny at the Illinois DH 2007 conference (accepted for publication in the LLC journal: Bradley 2008a), and it centered on how tools could be built to support annotation and note-taking as they are used in traditional scholarship, and then further how the computer could be used to support how the working with the digital note collection that came out of this could be transformed into a personal interpretation. Although Pliny, as a kind of thoughtpiece, reveals some interesting aspects of this, this area remains a topic that could usefully attract further attention within the Digital Humanities.
In this paper, however, I am focusing on the 2nd agenda for Pliny: one that focuses on how tool builders in the DH community could usefully be thinking about how many of their tools should be built. This paper grew out of a poster session also given at DH 2007 (Bradley 2007). This agenda talks about a new paradigm for software development (at least new to the DH development community, but also relatively new for the software development world at large) based around the Eclipse plugin paradigm. The plugin approach models a way to develop tools that can be simultaneously built by independent developers and yet still fit together in novel and useful ways. This paper, then, by being centered on this topic is really focused at the broad community of DH software developers.
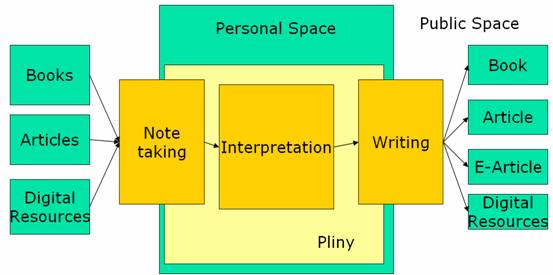
Figure I: Supporting work in the researcher’s personal space
Although agenda one and two seem to be quite different things, it is in the character of the issues that agenda one works with (notetaking, and its central role for many scholars in their scholarship) that influences agenda two. Let us begin here, then, with a brief look at agenda one. Figure I shows schematically what Pliny’s first agenda is all about, and it is useful to examine it before I move to focus on the main theme of my talk today – since part of my view about what makes the approach I took to build Pliny so interesting – to base it on the Eclipse plugin paradigm – grew out of the nature of annotation and notetaking itself.
In figure I you can see a representation of the role of the personal sphere in scholarship. Conventional humanities scholarship arises out of the personal musing of an individual scholar and Pliny is meant to fit exactly in this personal part of humanities scholarship. You can see there the area around the "personal space" which represents the "non-personal space" (often, but not exclusively "public") – the world of books, manuscripts, articles and, these days, digital resources such as web pages or PDF files created by others – both primary and secondary sources that make up the domain of materials that drive scholarship. In this model of scholarship, the annotation or note-taking activity that one does while reading represents a kind of a crossing of a boundary from the public to the private internal space one has read. Indeed, the writing of notes on a printed book makes clear both the separation between the public material on the printed page and personal reactions of the reader as the public part of the page is typeset, and the personal materials are recorded in the handwritten marginalia. The important thing to note is that there is simultaneously the need to combine the non-personal and personal materials together in a single visual space.
As figure I goes on to suggest, the notes that result from note-taking are the grist for the mill that grinds until a personal interpretation is produced by a scholar. Developing an interpretation is primarily an internal activity which, although based on input from many different external sources, is in the end a personal act. When an interpretation is deemed "ready" by its developer the traditional, and still usual, scholarly activity to make it public is to prepare it for presentation by writing it up in a text – resulting in a new book or article, or (only a little less traditional) perhaps some kind of electronic publication such as an article in an e-journal. Pliny is designed to support these three activities that reside primarily in the personal part of scholarship: annotation/note-taking, interpretation building, and writing up.
Pliny takes the approach to software first developed by Douglas Englebart way back in the 1960s (see, for example, Englebart 1962) but resulting in the now ubiquitous way to develop software for the personal computer that is shown by, say, the word processor. The word processor is a classic example of "Engelbartian" design – it doesn’t seem to do very much other than act as a receptacle for the work of the writer – but in fact what it does do is so useful that it is to now be used by the great majority of writers. Pliny aims to do the same thing as a scholarly note manager – it doesn’t seem to do very much either, but it provides a context for working with notes that is intended to make the user more effective in dealing with these notes.
Bradley 2008a and 2008b both show screenshots of Pliny at work, and I will not repeat them here. In one figure the user has annotated an image of the frontispiece of Vico’s New Science which provides, as it happens, a visual allegory of the text of the book itself. Most of the annotations associated important concepts that are found in the book with objects in the frontispiece image, but there are also a few notes that are not directly attached to the image but act as a kind of additional commentary. In the classic Englebartian manner, Pliny itself seems to do almost nothing here – the user manually annotates the images in ways that are interesting to him/her and Pliny simply stores them. A similar mechanism in Pliny is provided to support the annotation of pages of a PDF file. Notes can also be attached to web pages in Pliny as it comes to you "out of the box". Pliny can even be used to record notes about non-digital objects such as articles or books on paper.
An important idea of Pliny is that all the annotations for these different objects reside in a single repository – a note in a PDF file co-exists with a note attached to an image or to a web page, or derived from a non-digital source. This single repository for all Pliny objects attached to different kind of materials is important because Pliny is not only about annotation. It also provides an environment where its user can explore and organise the notes and the concepts that emerge from them in various ways until a satisfactory interpretation is developed. Pliny is not so much about the mature expression of an interpretation as about its development – thus, Pliny is in some ways pre-ontological and is meant to be used before a full structure has yet emerged. There is a description of how Pliny is designed to support interpretation development while it is pre-ontological in Bradley 2008b. Here again, the tool is primarily Engelbartian – the computer does not "generate" layouts for the user; the user does this him/herself. As the user explores the materials s/he has recorded by shifting around his/her materials in the space Pliny provides they will be assisted in developing their own views about how the materials might fit together.
We have now had a quick summary about what Pliny is about in terms of its first agenda. Let us now shift our focus towards the audience this paper is for: software developers active in the digital humanities. We begin this section of the paper by explaining what Pliny, as a piece of software, is not, and why it is not that thing.
First of all, the assumption these days among the digital humanities is that an application is going to be one based on the World Wide Web. There are, of course, reasons why we in the DH naturally think of everything being a web application – first, the technologies that we have readily available to many of us are based around XML and these technologies that support the development of sophisticated web applications are both powerful and, these days, well understood by many in the digital humanities. Second our user community already have and use the browser. Finally, the fact that a web application is based on the Internet means that it is potentially accessible from any internet-connected computer and thus allows us to focus on things such as collaborative creation of materials.
These are indeed fine things and worthy of our attention. However, from the perspective of the task Pliny is made to support – personal notetaking -- there are problems with web/browser based applications.
So, if Pliny is not a web application, is it then a software application like, say Word, your email client, or perhaps something like a KWIC concordance program?
Well, Pliny does indeed sit and operate on your own machine like other personal applications – but an important part of my message today is that it is not a conventional standalone application either: the way it as been developed provides for a type of collaboration between itself and other possible related applications which is both unusual and highly relevant to the needs of annotation.
Why does annotation need a different model for collaboration than that often practiced by other application developers? This is because annotation and note-taking represent a kind of a boundary application – sitting as they do between materials that come in from the outside world (a resource displayed by one application) and the internal world of the development of the interpretation (facilitated, in Pliny’s view, by a second application), and therefore represents a combining of a base resource application that displays the resource with one that supports the working with the annotation of it. Think of the hand-annotated page of a printed book. As I mentioned earlier in this paper, it combines the public materials (the print) with the personal scribbling in the margins,. On one hand the technologies involved, and the way of working with the texts they contain between the printed materials and the hand-written annotations are quite different. On the other hand – as in the printed page – the connection between the two is quite intimate – involving the actual sharing of visual real estate. It is this intimate connection of the screen between two different applications that is enabled by the way in which Pliny is written, and I will get to the way in which this is done shortly.
Annotation presents a particular challenge to conventional digital application development in that to be particularly useful it needs to be applicable across a range of different digital applications and simultaneously needs to store the annotations in such as way that the researcher can bring them together. The digitally aware scholar will quite possibly want to annotate everything s/he works with and this doesn’t just mean a range of different web pages or PDF file pages. Perhaps s/he will wish to annotate the result of processes that are applied to their materials – annotate a KWIC display, for example, or the results of a graph emerging from some sort of statistical process. Now, these objects are no longer fixed web pages or PDF files, but represent dynamic displays created through the running of a separate computing process – a specialised application such as a statistical program. It is in the need in annotation to combine two applications simultaneously and equally on the screen at one time that traditional application design – which focuses on a screen to support only one application in each separate window – runs into trouble.
Conventional application development focuses on the development of an application that does a coherent set of functions. Imagine, for a moment, three tools: one to do some sort of linguistic analysis, one to do keyword identification in a text, and another to take geographic references in a text and place them on a map.
The ability of these quite different applications to all read a common file format – say one built on XML in, say, TEI – is a significant aspect of allowing the three tools to all operate on the same source material, and the user can, simultaneously, have three windows open on the screen – one for each of these application, and s/he can juggle among the three open windows as his/her focus of attention shifts between the things each of them are showing.
A wish to support personal annotation, however, challenges the separate application/separate window model since a researcher might well wish to annotate materials s/he is seeing from each of these three applications, but still bring these annotations together. Of course, each application could develop its own annotation function (indeed, there are currently existing pieces of software that I know of that handle user annotation in exactly this way), but this results in three independent annotation systems, each with their own way to do things and each with limitations due to the fact that the developer of, say, the linguistic analysis program only has personal annotation in there, if at all, as a secondary priority. Furthermore, any researcher whose work spans a set of separate tools built in this way is faced with a problem when trying to bring together for further consideration the notes s/he has made that respond to what the three tools have shown him/her. Not only are the annotation tools provided, if provided at all, in each tool limited in function, they are different in how they work and what functions they provide. Furthermore, the annotations s/he makes in them belong only to the application in which they were made.
Pliny is developed in a framework that, simultaneously, allows for both the specific functions of independently developed tools to co-exist with a shared annotation mechanism. The way this is done is through Eclipse’s Rich Client Platform (RCP) approach to software development (for a quite detailed technical introduction to RCP see McAffer 2006).
"Wait a minute" – I hear you say – Eclipse is a tool to develop Java programs – a so-called IDE. How is that remotely relevant to the quite different task of giving humanities researchers access to tools such as annotation or linguistic analysis tools?
Eclipse, when you fetch it from eclipse.org and install it is indeed focused on Java software development, and indeed this task can be extended by the addition of helper tools in the form of "plugins". However, the difference between an Eclipse application in its use of plugins and, say, plugins in a conventional application such as an image manipulation program like Photoshop or a web browser with its plugins such as Firefox, is that Eclipse does not have a large mass of code that represents it’s "primary" purpose as a tool to support Java software development. Because the non-plug-in part of Photoshop is all about working with images, a plugin for Photoshop is almost guaranteed to do something with images – the focus of Photoshop itself. Similarly, a plugin for Firefox is almost guaranteed to work with web pages – the focus of Firefox. Instead, Eclipse comes with a bunch of smaller packages of software called plugins that work together to provide a sophisticated Java development tool. In Eclipse there is no large mass of code outside the plugin model that represents the "central Eclipse application" – writing Java programs. Instead, the Java application part of Eclipse is delivered as a set of plugins as well. In Eclipse, everything is a Plugin. An application can be created by a developer as a set of co-operating plugins that operate within the framework provided by the Eclipse environment.
By packaging up Eclipse virtually entirely as a set of plugins, the Eclipse designer allowed for the possibility that Eclipse might provide a framework to do something else entirely -- take away the plugins that support Java coding and replace them with plugins that do something else and Eclipse will stop being a Java IDE and start being something else altogether. Furthermore, combine plugins that make up two or three separate applications in a single Eclipse application and Eclipse will appear to do all of them at once.
Behind the set of plugins that support a particular application such as Java program development are a set of more basic plugins that provide a base framework that all the application plugins can share. These plugin components together make up the "Rich Client Platform" – or RCP.
Among other things, the RCP manages for the other plugins a rich basic window interface which all the plugin applications can share that provides support for the management of separate panes on the screen, a common approach to a shared menu and toolbar, a common approach to help, and a number of other things. Once a user has learned how to, say, add or move a pane on the screen in the way that RCP supports it, the same technique will be used no matter what actual application/plugin s/he is using at the time since the same RCP framework provides this kind of functionality for all the other plugin applications it is working with.
In the Eclipse RCP, then, the application programmer doesn’t have to write code to handle this basic stuff at all. This not only speeds up software development, but also helps the user since s/he will find that in all the Eclipse-hosted applications s/he uses, these basic operations are done in the same way. This is because the same RCP provides these operations for all applications it hosts. This, in turn, reduces the amount of learning a user has to do when starting to use a second application that runs in the Eclipse RCP once they know their first one.
When one starts an Eclipse RCP application on your computer one first starts the RCP framework. It, in turn, looks in its plugin folder and sets up all the plugins it finds there so that they are ready to be used if the user calls on them. Setting up a new application simply involves placing the relevant plugin or plugins into your RCP plugin folder, and RCP even provides a mechanism that can fetch such applications over the internet so that the user doesn’t have to drag files around at all.
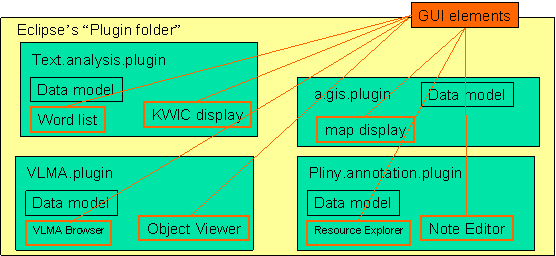
Figure II: Plugins
In figure II we see a schematic representation of an Eclipse plugin folder, with the darker boxes representing different plugins that provide different applications. We can see in the figure a plugin that provides a text analysis application, one that supports a GIS application, one that supports a VLMA application (more about it later), and we can see Pliny as a plugin as well. Note that a plugin is not only the code that works with its relevant data, but also can contain a set of graphical display objects that can, say, be displayed in an Eclipse RCP pane, or appear as items in a common toolbar, or can provide a set of help pages. When Eclipse RCP starts up the user will see a kind of workspace screen that gives access to all these tools from one place, and, since the RCP window can be divided into panes the user has the ability to mix and match displays from these different applications together on the one window’s screen.
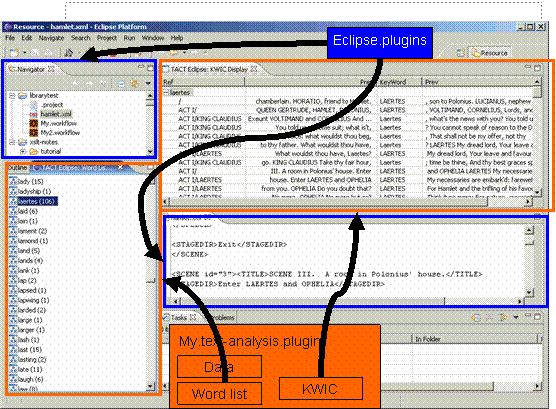
Figure III: Applications sharing a Window
Figure III shows this at work, with the Eclipse RCP screen combining elements from the main bundle of basic panes provided by Eclipse – the file navigation tool and a basic text display, with tools that are specific to an application developed not by Eclipse but by an independent developer – here a text analysis program that parses an XML text for words, shows the resulting word list in one pane and a KWIC concordance for any of these words in another.
The consequence of the plugin approach of Eclipse is that:
Although I am promoting the Eclipse model to you here, and am doing so in part because of the particular boundary nature of annotation, Pliny is not the only tool for the digital humanities built in this way. Indeed, I first began to think about Eclipse plugins and their potential for tool development in the Humanities when I heard a presentation by Kevin Kiernen and his team (see Jaromczyk 2003) from the University of Kentucky on their EPT system which is part of the Archway project (Kiernan et al 2005) – which is built on top of Eclipse. Some of the ideas I describe in these paper actually come from them. Also, as I understand it, the Eclipse plugin model forms the backdrop to some of the tools being built for TextGrid (TextGrid 2008). I think that any of you who are building applications that work like toolkits or workbenches should also think of the Eclipse/plugin approach.
The significance of the development of independent but simultaneously collaborating applications can best be seen by briefly considering a few examples. I have three to show you – all three are prototypes and certainly not ready to be distributed to a user community, although with more work they could be turned into fully-functioned applications.
This first one shows a plugin which acts as a supplement to basic Pliny and provides a mechanism for annotating a Google Map. You can see a screen-shot of it in operation in Figure IV. The map itself is displayed in the embedded web browser that is available in Eclipse as a GUI widget. A combination of Java programming for Eclipse/Pliny and Javascript for the browser, plus the use of the messaging system available between them makes this annotation plugin possible.
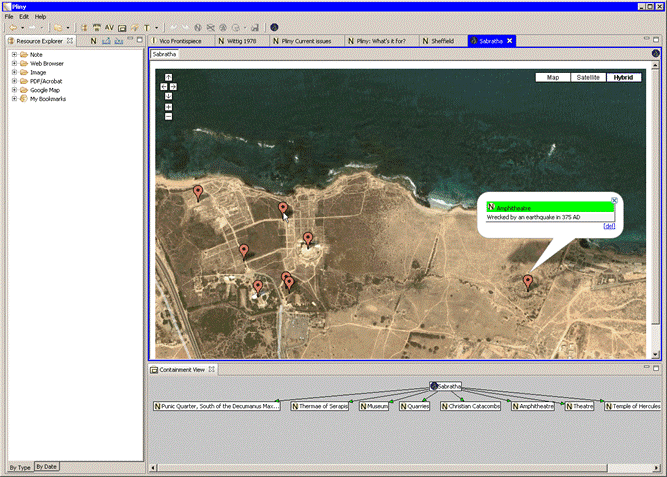
Figure IV: Google annotation and Pliny
The Google Map annotator is not a tool provided in base Pliny as you fetch it from the Pliny website, but after I developed it as an add-on it was easy to install in the standard Pliny package – I simply took the plugin bundle – packaged up as a Java JAR file – and placed it with the other plugin JARs in Pliny’s plugin folder. When I next started up Pliny the start-up process noticed that it was there and made it available to be used.
There were two immediate visual consequences of that:
Now that the Google Map annotator is there, the user can use it. Here we see the situation that develops when the user wishes to generate an annotated satellite image of the Sabratha archaeological site in northern Libya (if interested, see some information about Sabratha at the World Heritage site webpage at World Heritage 2006). I am thankful, by the way, for the data you see here which was provided by my friend and colleague Hafed Walda at CCH.
To start creating the map the user clicks on the button to launch a new Google Map annotator pane, and then navigates and zooms in on the place in the world where Sabratha is. The final scale, image type and position is noted by the plugin and stored with the newly created resource so that the next time it is opened the satellite image will be centred in exactly the same geographic place and shown to the same scale. Now that it is positioned the user types in the name of this new annotated resource in the top left text box. A Google Map Pliny resource object is created that records the characteristics of the Google Map display at this point, and this object is filed under the name just provided to it in the Google Maps section of the Resource Explorer. This newly created resource can mow be used in all the ways that any other Pliny object can be used.
Now that the map is positioned the user adds geographic spots to be annotated (called, in Google Map parlance, markers) by double-clicking on the spots. The plugin launches a window into which a title and content of a note can then be specified and this is simultaneously created as both a new Pliny Note, and also passed to the Google Map API so that a new marker is created for it on the displayed Google Map image. As Pliny’s containment view (shown at the bottom of the screen) makes clear, Pliny also knows that these notes are connected to this resource. Now, whenever the Sabratha resource is opened the Google map image will be recreated as the user left it and the notes that have annotated it are redisplayed as markers with attached Google Map comments. We can see one of the comments displayed here (unfortunately, the Google Map API seems to allow only one to be open at a time) – created to display like a Pliny note.
In the prototype only textual notes can appear as annotations – but conceptually at least it is easy to allow other Pliny objects to appear – an image of the place noted could be first identified as a Pliny image resource, and then attached as an annotation to the spot on the map.
We have seen, then, a Google Map annotator integrated into the Pliny context. The application was not difficult to write once one understands the necessary Pliny and Eclipse APIs – I mocked up this admittedly incomplete plugin in about 3 days of coding. A similar activity of creating a new plugin could be undertaken to add, say, a new annotator for a video or sound file.
My next example – also a rather basic prototype – shows how annotation might be added to an independently created application. I chose a traditional text analysis prototype example – here with very limited functionality (because of its prototype status).
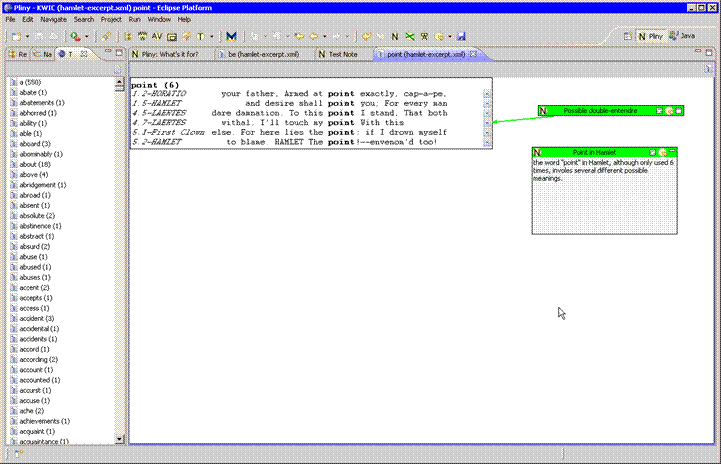
Figure V: A text analysis plugin collaborating with Pliny
This prototype reads an XML file it is given and parses it for both words and tagging structure. The plugin contains a view object that displays the resulting word-form list (shown here positioned to the left), and the user can double click on any word or group of words in that list to launch the KWIC display which will open in the main pane. The KWIC concordance pane is outfitted with a connection to Pliny so that results there can be annotated, and any generated KWIC concordance is given to Pliny as a Pliny resource and so can, itself, be referenced from other Pliny objects.
Figure V shows the result of first directed this plugin to an XML file containing the text of Hamlet and then choosing the word "point" from the generated word list. A KWIC display of "point" appears in the main window. While examining the KWIC display the user noted a couple of things that tweaked his interest and created two annotations which are displayed here, but also stored in Pliny. One of them is attached to a particular word token in the text; the other is a general comment about the complete list of "point" words. Like any other Pliny annotated resources, these comments will appear any time in the future I open this KWIC concordance.
Imagine that after examining the uses of the word "point" the user becomes interested in references to rapier fighting in Hamlet. S/he could then launch Pliny’s embedded web browser and searches for articles about the subject – and perhaps will find several. Perhaps one of interest will be the article by James Taylor in the Forum for Modern Language Studies (Taylor 1993) which s/he can then read in the Pliny’s standard PDF viewer, and can annotate there. We see this going on in figure VI.
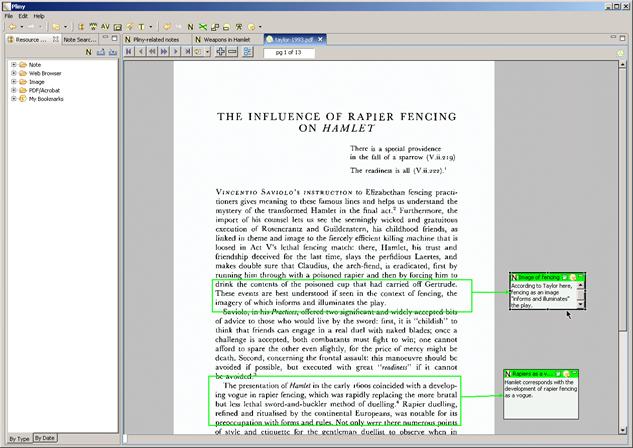
Figure VI: Annotation in the integrated PDF viewer
After finding more relevant articles, the list of interesting objects related to this "fighting in Hamlet" topic is a set of annotated documents and a set of words from the play that can be displayed by the text-analysis plugin as KWIC concordances – and these might be annotated as well. Note that, as is perhaps not surprising, the user’s research has gone outside the confines of computer assisted text analysis. By having an integrated note-taking tool that works with both the text analysis tool and with other kinds of digital resources the user is able to manage his/her notes across all the materials that interest him/her in an integrated manner.
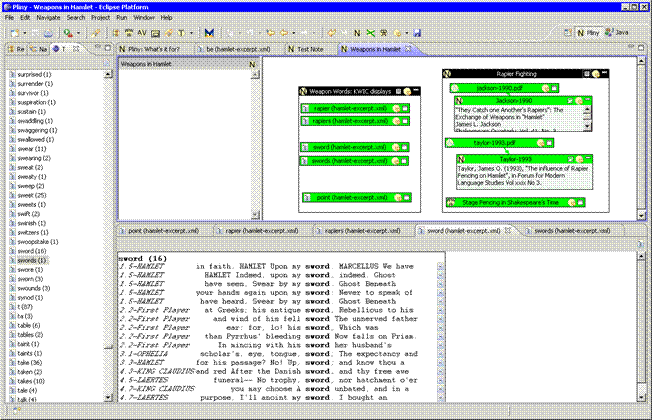
Figure VII: Organising a topic in Pliny
Perhaps the user has become interest in the broad topic of Weapons as referenced in Hamlet. Figure VII shows the user after s/he has created a Pliny note to keep track of all this: recording references to the collection of relevant objects s/he as discovered so far. You see it here in the top part of the screen in figure VII. This organising note entitled "Weapons in Hamlet" has its reference area divided into two groups – one of which contains references to things that s/he has read that related to fighting in Hamlet, and the other containing links to resources created by the text analysis tools that are KWIC concordances for some of the words that related to fighting. If one double clicks on the reference the corresponding KWIC concordance (possibly with its own annotations) will open. We can see here in the bottom area the display for the word "sword" which was opened by double-clicking on its reference in the top area.
I hope you can now perhaps begin to see the advantage of being able to combine separate applications, as separate plugins, and to allow them to interact in ways that involved both their common data but on the screen as well. The top area in Figure VII refers to several different resource types displayed by separately created plugins, including a web page, two PDF files, and the WIKI displays. The combined-yet-separate nature of the plugins makes it possible to provide this kind of integration at little additional cost to the software developer for any of these tools.
We now move to look briefly at the third example of a prototype plugin. This is based on the work of the VLMA – the Virtual Lightbox for Museums and Archives (VLMA), a framework developed by University of Reading, the Max Planck Institute for the History of Science and Oxford Archaeology (VLMA 2006) which gives a user access to an RDF server managing metadata about images, and the images themselves.
The VLMA team have developed a way to describe museum artefacts in RDF that can be served from an RDF server. They also developed a Java application (expressed both as a standalone application, and as an applet) that can then query one or more servers for metadata about the objects the servers know about and allows the user to browse or query one or more of these collections for images of interest.
In figure VIII we see a display from the plugin I developed that mimics part of the VLMA standalone application. Parts of its code are, of course, taken directly from their publicly available code since all the data-specific coding that interacts with the RDF server could be used more or less exactly as it had been in VLMA’s standalone application. However, the interface end of the software had to be somewhat re-thought to express it in the ways that seem natural to Eclipse plugins and RCP. This prototype was put together with about 2 weeks of coding and is, like the other two examples, actually incomplete, but sufficient to show the basic ideas here.
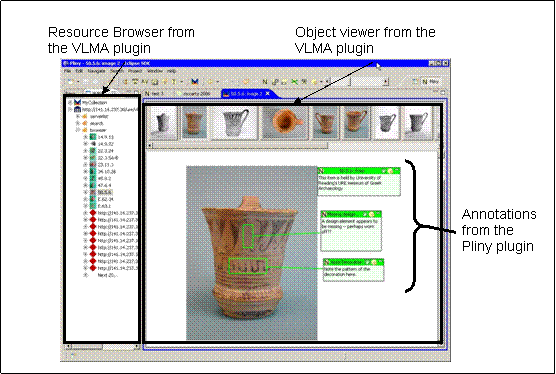
Figure VIII: A VLMA Plugin
The advantage of running the VLMA application as a plugin is that when the VLMA plugin shares its space with the Pliny plugins it can provide annotation services provided by Pliny rather than either not having annotation at all, or having to build its own. Furthermore, as we have already seen, because of the co-existence of VLMA and Pliny in the same workspace, annotations attached to VLMA objects go into the Pliny pool where they can be combined with annotations and notes attached to other objects.
Figure VIII shows the VLMA plugin in operation. The left panel shows the VLMA navigation pane which is similar to the one provided in the VLMA standalone application but is packaged as an Eclipse view. When one chooses an object in this view the plugin’s image viewer and annotator opens shown in the larger right panel. The user has attached three notes to this particular image and attached two of them to specific spots in the image. Again, then, we see this blending of the Pliny and VLMA applications appearing together on the screen.
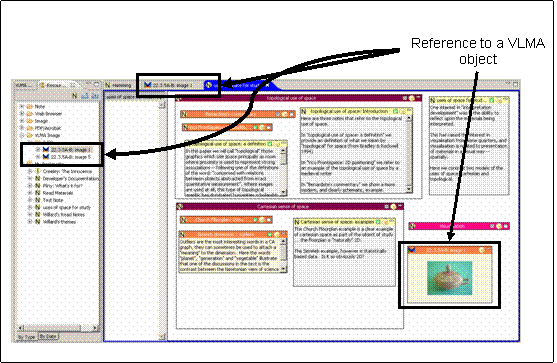
Figure IX: VLMA objects imbedded in Pliny
Figure IX shows the advantage of the kind of close collaboration between software that the Plugin model provides from the opposite perspective. Here the screen is made up mainly of Pliny panes – but there are references to objects created by the VLMA application in them. The standalone VLMA viewer’s designer needed to provide a light-box application in their application so that images from several different objects could be brought together in the same visual space. I did not feel the need to recreate a light-box when VLMA was written to co-operate with Pliny because Pliny’s 2D space can provide the same function as the light-box on its own. Furthermore, because Pliny’s space is not specific to VLMA, it can contain references to objects other than VLMA ones, such as images harvested from the WWW, or references to related web pages or PDF files. When VLMA and Pliny co-exist, the user can manage both collections of images of interest drawn from VLMA, but also references to related digital objects outside of VLMA as well. In the Eclipse plugin context the user can combine references to objects located in a VLMA space with references to those objects in, say, PDF files that someone else has written about them.
By now I expect it is clear what some of the advantages of the plugin approach to software development are – particularly for the annotation-end of Pliny. However, the potential benefits go beyond these.
We have seen here how a collection of plugins that could have been written by others can be created that work with Pliny to provide integrated annotation support to a range of data types. In all three of our examples shown in this paper, the plugin has provided annotation support for a different kind of digital resource. However, plugins could supplement the work of Pliny in entirely other ways as well.
Two examples:
Eclipse uses the language of contribution to describe the ability of one application to enrich the displays of another. We have seen three prototype plugins that both provide their own functionality, but also gain in their ability to provide annotation services by allowing a contribution from Pliny to provide for them an annotation function, and allows Pliny to recognise and display items created in the other plugins as contributions to it. Other plugins could certainly be written that operated in a similar fashion.
However, interactions between other tools could be facilitated that were not about annotation at all. A statistical package, say, could be packaged as a plugin in such a way that it allowed another plugin perhaps developed by someone else to contribute to its function by adding, say, a new type of statistical display. Indeed, it is exactly because the contribution model allows for functionality to be extended relatively easily that other groups are taking up the Eclipse plugin model as the basis for building large, sophisticated and extendable workbench-like applications.
So, if the Eclipse plugin model for software development is so flexible and apparently a platform appropriate for the development of tools for the DH, why aren’t others in this DH tool-developing community anxious to take it up?
I think it is because the benefits come with costs attached:
Furthermore, there is reluctance within the DH community to create anything other than web applications for humanists not only because we already know how to do them, but because we believe that the humanities users are more likely to take them up if they are based on the browser which, it is assumed, they already know how to operate.
I’m not at all convinced by the assumption here that people in the humanities will not learn a new application even if it supports their research interests. At one time academics did not use word processors, email or the WWW. They found learning all these things difficult at first, but they took them up because they were obviously useful to support their activities. There is, in fact, then, evidence that if the write tool comes along that clearly supports their interests, they will be prepared to learn it too.
Perhaps Pliny could be this tool. Pliny has been developed based on the ideas that a note-taking tool and framework would also be useful to support humanities research. A new Pliny user would have to learn how to operate it, but, since Pliny is built in the Eclipse RCP many of the ways of doing things are standardised by the RCP itself (opening and closing thing, moving things around on the screen, etc). Once they learn these things for Pliny they can reuse this knowledge when loading any new RCP-based application – therefore reducing the burden involved in taking on something new, and I hope I have suggested here that RCP-based applications could usefully cover the full gamut of applications currently developed for the Digital Humanities, from text analysis to image manipulation.
So, in conclusion, I am convinced enough of the merit of the Eclipse plugin approach that I think that all tool-builders working in Java should consider building their tools as Eclipse plugins – particularly if the development team is dispersed between several different organisations and the resulting independently built software has to fit together.
If you are interested, you and your developer team will have to become familiar with the Eclipse plugin development model. The Eclipse website itself (Eclipse 2008) provides a significant range of documents that describe aspects of this. The IBM DeveloperWorks website Recommended Eclipse reading list provides a good set of starting points for developers (Aniszczyk 2006). Furthermore, there is some introduction materials for developers available at the Pliny website (Pliny 2006-8), including the full JavaDoc for the Pliny code, and a separately written introduction to the Pliny API. The Pliny source code is available from SourceForge. Please take a look, and let me know what you think.
Aniszczyk, C. (2006). "Recommended Eclipse reading list". In IBM DeveloperWorks website. Online at http://www-128.ibm.com/developerworks/opensource/library/os-ecl-read/ (referenced August 2008)
Bradley, John (2008a). "Thinking about Interpretation: Pliny and Scholarship in the Humanities", Literary and Linguistic Computing. accepted for publication.
Bradley, John (2008b). "Pliny: A model for digital support of scholarship". In Journal of Digital Information (JoDI). Vol 9 No 26. Online at http://journals.tdl.org/jodi/article/view/209/198.
Bradley, J. (2007). Making a contribution: modularity, integration and collaboration between tools in Pliny. Poster paper at DH 2007 conference, Urbana-Champaign: University of Illinois. Online at http://pliny.cch.kcl.ac.uk/docs/Illinois-Poster.pdf (reference August 2008).
Eclipse (2008). Eclipse website at http://www.eclipse.org (referenced August 2008)
Englebart, D. (1962). Augmenting Human Intellect: A conceptual framework. Stanford CA: Stanford Research Institute. Online at http://www.bootstrap.org/augdocs/friedewald030402/augmentinghumanintellect/AHI62.pdf (Accessed March 2007).
Jaromczyk, J Wl. and Sandeep Bodapati (2003). "An Architecture Promoting Collaborative Research, Teaching and Learning,". In Program for the Joint International Conference of the Association for Computers and the Humanities and the Association for Literary and Linguistic Computing. The University of Georgia, 29 May-2 June 2003.
Kiernan, K., J. W. Jaromczyk, Alex Dekhtyar, and Dorothy Carr Porter, (2005). "The ARCHway Project: Architecture for Research inComputing for Humanities through Research, Teaching, and Learning," Literary and Linguistic Computing (2005), 1-20.
McAffer, J. and Jean-Michel Lemieux (2006). Eclipse Rich Client Platform: Designing, Coding and Packaging Java Applications. Upper Saddle River NJ: Addison Wesley. pp. xxx, 504.
Pliny (2006-8). Project website http://pliny.cch.kcl.ac.uk/. (Accessed November 2007).
Taylor, James O (1993). "The Influence of Rapier Fending on Hamlet." Forum for Modern Language Studies 29 (1993): 203-215.
TextGrid 2008. Project website at http://www.textgrid.de/index.php?id=startseite&L=5 (referenced August 2008)
VLMA 2006. Project website at http://lkws1.rdg.ac.uk/vlma/ (referenced August 2008)
World Heritage 2006. "Archaeological Site of Sabratha". In World Heritage website. Online at http://whc.unesco.org/en/list/184/ (referenced August 2008)